
Noteworthy Image Search
August 2007 - June 2010
Course: PhD project
Software: C++, with libcurl, libxml2, tinyxml, cximage
libraries, XAMPP with PHP
Description
This text-based internet search engine finds the newest images
for any particular query, especially for noteworthy imagery,
i.e. "what are the newest images for 'Star Wars' since my last visit?".
To do this, we keep track of images as they are downloaded, cluster
them by similarity and determine by date which ones are new. The
similarity clustering is done by using descriptive keywords extracted
from the page the image was found on and by using content features
extracted from the image.
Image crawler
One of our first goals is to download as many images as we can find on
the internet, as fast as possible. The fact that the internet is very
very large - Google recently visited its 1 trillionth unique URL - and
constantly changing, makes this a formidable task. Without large
quantities of storage, memory and processing power available, careful
thought is required in order to make this task manageable.
Over time our design has evolved from an approach trying to use the most modern techniques to its current form that uses old-fashioned, proven and robust methods. In the initial design, the image crawler consisted of a manager thread and many worker threads that all were concurrently accessing the open source transaction-based Oracle Berkeley DB to read/write link and image URLs and image data. In theory it worked beautifully, however we soon found out that this approach had several drawbacks. Even though threads share memory space with the host process, so they can easily exchange information, they are notoriously hard to kill when they go haywire and can crash the entire process when they do so. Also, many available open source libraries are not thread-safe, or only allow one thread at a time to use certain functionality. This can of course be avoided by writing each library ourselves, but it should not be too hard to imagine that flawlessly replicating and improving existing functionality is not easy and extremely time consuming. As a final problem, the database caused our performance to grind to a halt when it was pummeled by large numbers of simultaneous requests. Even thought the database is well-known for its robustness and high performance, it is designed for handling large number of read requests (e.g. a airline travel database) and not for large number of write requests, which is what our crawler requires.
Realizing that communication between manager and workers does not have to take place directly, we arrived at the current design, see Figure 1. At the moment, the manager and the workers run in separate processes and communication between them takes place using simple plain files on the hard disk. The manager prepares files containing unique URLs for the workers to look at, and the workers write files containing any URLs they have discovered. This approach instantly solves the thread-safety issues with existing open source libraries, and also relieves us of the need for a database that is accessible by multiple entities at the same time, because now the manager is the only one who needs access to it.
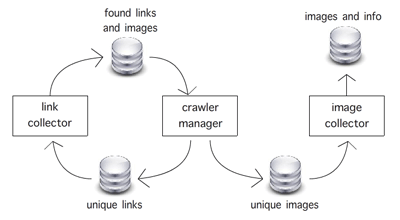
Figure 1. Communication between crawler manager and workers.
With the billions of links present in the internet, providing a uniqueness check for URLs requires some thought. As the check needs to be fast, all URLs must be kept in memory. However, storing each complete URL in memory and comparing URLs character by character quickly becomes infeasible storage- and processing-wise. Therefore we represent each URL by hashing it to a 64-bit signature, using an adapted version of MD5 (Message-Digest algorithm 5), which is a widely used but partially insecure cryptographic hashing function. It has as strength that highly similar inputs will hash to completely different outputs, and thus it will rarely occur for URL signatures to collide. The signatures are stored in a hash tree, which is a combination between a hash list and a binary tree, allowing for a fast uniqueness check.
Our crawler is a nice crawler, because it looks at the robots.txt file of a site and follows the specified rules. In addition, the URLs that the manager hands out to the workers are randomized, to prevent accessing the same web server too many times in a row.
Keywords and copies
The image information gathered by the image collectors is still in a
raw format and needs to be processed before it can be used by the
search engine. The raw information describes the title of the page the
image was found on, the text surrounding the image, and so on. From
this information descriptive keywords are extracted, which will allow
user to search for images by typing in these keywords. As a special
functionality, we have built in preliminary support for language
detection, so that the keyword extraction can be done more efficiently
and people will be able to choose the language of their choice during
searching.
To ensure diversity in the presentation of the found images as a result of a search request, we perform (near-)copy detection. To achieve this, we have selected the best copy detection algorithm from experiments we have performed, see the copy detection project page for more information.
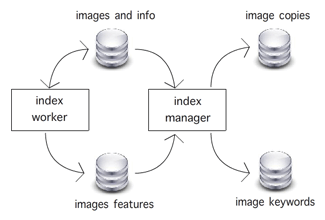
Figure 2. Communication between index manager and workers.
To enable fast processing, many concurrently running index workers extract keywords and features from the images. The index manager gathers the keywords and stores them in a database, and also compares features to detect image copies. See Figure 2 for the current design.
Search engine
Because each image is associated with descriptive keywords, users can
easily search for images using text. As mentioned before, we can
present the user with a more diverse set of image results using our
copy detection algorithm. We collapse copies and near-copies of images
into one representative image, thus leaving space for more image
results.
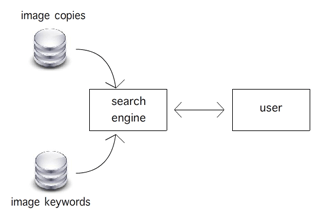
Figure 3. Interaction between the search engine and the user.
At the moment, the search engine is available for internal testing only. We will need to incorporate a few extra things in order to make it fully usable for the general public. One thing is that we need to answer the question of what makes an image ‘noteworthy’. This is a difficult question, which makes it one of the main research aspects of this project. To take it to the extreme, for a movie fanatic user anything related to movies is noteworthy and everything else is not. However, because we want to cater to the general public, we should broaden our scope. Many different techniques can be used, but initially we are thinking about looking into neural networks to learn to detect when an image is noteworthy or not. Also, we need to keep track of user identities to provide additional services. For instance, each image is tagged with the date it was downloaded, so once we know a user is interested in a particular topic we can show the newest images on this topic that the user hasn’t seen yet. Finally, we want to think about ways to propagate keywords from images that have them to images that do not have them. A way to achieve this would be to determine similarity between images by analyzing their pictorial content, so that an image that has no or few keywords can inherit them from another image which is highly similar to it.
Publications
The noteworthy search engine will be discussed in the upcoming Eureka
magazine issue.