
Scene Completion
November 2009 - June 2010
Course: PhD project
Software: C++ and MATLAB, with cximage, cxsparse, TOP-SURF, GIST
and graph cut libraries
Description
The initial query image is of paramount importance when searching for images of interest, because it has a direct effect on the retrieval results. The image that is chosen as the query image is of course similar to what the user is looking for, but nonetheless often does not fully represent what the user has in mind. The selected image for instance may contain elements that are not relevant to the user’s intention. Our assumption is that the presence of these elements negatively impacts the performance of the search engine, causing the retrieval results not to be as good as the user would like them to be. One reasonable explanation is that this happens because the user looks at an image from a high-level, i.e. the query image contains the general concept the user is interested in, even though this is not necessarily completely reflected by its content.



Figure 1. Erasing unwanted elements from photos: original scene (left), scene with the car and its shadow masked out (middle), touched up scene where the car is seamlessly replaced by a rock and a tree (right).
For instance, suppose that the user is looking for images that show a view of the Grand Canyon and she uses the image shown in Figure 1a. To us humans it is obvious her intention is that the car should not be considered by the search engine, rather only the scenery from the other parts of the image. Yet, traditional search engines will have no idea of the user’s particular intention and simply use all image content. In the most positive scenario the retrieved images may be other scenes containing a similar view with a car, although it is certainly possible that they might as well be scenes that focus on cars, or be scenery that contains a large green object. Either way, the presence of the car is very likely to have a negative effect on the retrieval results from the point of view of the user. Our aim is thus to allow the user to erase such unwanted elements (Figure 1b), and to let the resulting hole be seamlessly filled with semantically valid (i.e. plausible, realistic) content that more closely reflects what she has in mind (Figure 1c).
In a sense the retrieval system is thus artificially imagining scenes; see the virsi project for an introduction to our novel artificial imagination paradigm. In comparison with the images that are returned by the search engine when using the original (unmodified) scene as the query image, we expect that the search engine will return more relevant images when the hole-filled scene is used instead.
Scene Completion
To allow the user to erase undesired parts of a query image and to
consequently fill the resulting missing pixels with desired content, we
incorporate the scene
completion technique, which was recently proposed by James Hays and Alexei Efros, into a search
engine. The scene completion technique attempts to find semantically
similar scenes to the incomplete query image and identifies the best
image patch that matches the context around the missing region. This
patch is then seamlessly blended into the image to complete the scene.
The usefulness of this technique is easy to understand: too often the
photos that we take contain unwanted elements, such as a few tourists
that happened to wander into the scene or a piece of fence partially in
front of a beautiful statue. The scene completion can be used to
replace these undesired elements by something else that not only is
appropriate, but also is done in such a way that the replacement region
blends in with the old scene in a credible way.
One of the most fundamental aspects of this method is that a very large image collection is required in order to find suitable candidate image patto fill in the hole. The experience of both ourselves and the original authors is that a small collection of, say, ten thousand images provides insufficient matching quality and the resulting composite images don't seem credible enough. On the other hand, when using a collection several million images the chance of finding at least one suitable region goes up appreciably, and resulting completed scenes look quite realistic. To this end we used our flickr crawler, which we originally developed for the copy detection project, to download several million images related to travel, landscapes and cityscapes, because these belong to the category of image search we had in mind.
For an image patch to be blended into the incomplete scene in a plausible way, it must be graphically, contextually and semantically valid. These three conditions each operate on a different level of image analysis, with the graphical condition operating on the low-level, the contextual condition on the mid-level and the semantic condition on the high-level. When the conditions are not met, the resulting images don't look realistic. See Figure 2 for illustrations of the validity violations.






Figure 2. Image patches that violate the graphical condition (top, the beach sand is too rough compared with the sand in the query image), contextual condition (middle, the brown bear turns greenish) and semantic condition (bottom, a cloud in the blue sky is replaced by a jumping person) when blended into an incomplete scene
To find suitable image patches, the system first attempts to find the images from the database that best match the query image, while ignoring the area behind the mask that the user has drawn. To find these best matching images, the system uses the GIST descriptor of Aude Oliva and Antonio Torralba together with an L*a*b* color descriptor. Once a small set of candidate images has been found, a local context matching algorithm inspects the images in more detail, to find image patches within them that are likely to be smoothly placed into the hole of the query image. For each image patch a scene is created into which the patch is blended by using the graph cut textures technique proposed by Vivek Kwatra et al., which first applies Yuri Boykov et al.'s graph cut technique to find the optimal seam and then seamlessly blends the images together using Patrick Pérez et al.'s Poisson blending approach. Finally, the scenes that incurred the least transformation costs during each of these steps are the ones that are returned to the user.
Image Retrieval System
We are in the process of testing our hypothesis, whether or not
removing unwanted image elements is beneficial to the retrieval
performance, but have no results yet. When more details come available,
we'll update this page to include them. To give you a glimpse of our
set up, we show an overview of our retrieval system in Figure 3.
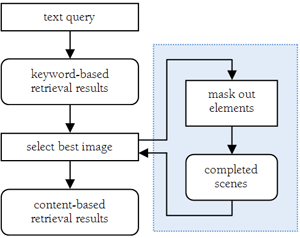
Figure 3. Overview of our retrieval system, with the scene completion component highlighted on the right hand side