
The Matrix - Next Generation Social Interaction
January 2006 - April 2007
Original name: Immersive and Spatial Voice Audio in Networked
Virtual Environments
Software: C/C++
Description
Visions of the future such as The Matrix, The Street (from the book
Snow Crash), or Cyberspace (from the book Neuromancer) all support
audio and visual communication in a way which works naturally with
reality. In the virtual world, when someone walks around a corner, you
no longer see him nor hear him. The promise of virtual reality has been
within the public consciousness for decades, however, the technology
for achieving an immersive experience has only been available fairly
recently.
In the current work on multiplayer virtual reality, the research has
focused largely on the visual aspect combined with text. Audio is often
neglected and when present typically ignores the structure of the
virtual world. In this project we have created a new system which
integrates the audio, visual and 3D structure of the virtual world.
Specifically, our novel contribution is the creation of a system which
models the effect of the 3D world structure upon the audio and visual
aspects in a natural and intuitive manner: players in the massive
multiplayer world can now talk with each other as in real life.
Client and server architecture
Besides providing clients in the virtual world with a realistic audio
experience, we wanted to achieve the following:
- Allow a large number or clients (>100) to connect
- Require only moderate bandwidth (~128kbps)
- Work from behind routers and firewalls
- Maximize portability (any virtual world can be used)
The central server architecture - where all clients connect with a
single server - was our optimal choice, fullfilling all design goals.
More advanced architectures would definitely result in more clients
being able to connect, but would have a downside that the system will
be much more complex and less easy to set up and get running. To
illustrate our audio system, we integrated it in the Quake 3 game. This
game has the advantage of being open source and well-known for its low
bandwidth usage. Note that any other game could have been used instead,
provided access to the source code to enable it to use our audio
framework.
Sound attenuation
We have modeled how the distance and angle between sounds and listeners
affects the audio perception and additionally devised a novel algorithm
to handle structural audio attenuation. The structural audio problem
occurs when the 3D structure interacts with the audio signal. Examples
include simply going around a corner or walking into a room and closing
the door. In both cases, the 3D structure affects the audio – typically
lowering the amplitude but potentially also causing audio reflections
and refractions. For structural audio, we can not simply cut off the
audio when a wall is in between a sound and a listener, rather we must
have a natural drop off due to the interference with the 3D world.
Our novel structural audio algorithm employs Cauchy’s probability
distribution, see Figure 1, to weight a grid that is placed with its
center at the listener’s location, pointing at the origin of the sound.
The weights near the center of the grid have higher values than those
along the edges.
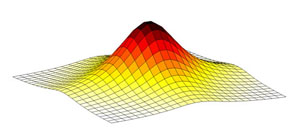
Figure 1. Cauchy probability distribution
The ‘audibility’ of each point on the grid its determined by tracing the visibility between itself and the sound, see Figure 2. The attenuation factor is formed by adding only the weights of the grid points that are ‘audible’. This technique results in smooth sound transitions when moving around objects and corners while talking to other players.


Figure 2. Tracing visibility using the Cauchy-based grid: with
direct line-of-sight (left) and a
partially obstructed line-of-sight (right)
Our audio algorithm utilizes the Cauchy
distribution because it (a) has been shown in other areas to be more
realistic to real world distributions and (b) in the future will allow
us to adaptively adjust its parameters, e.g. simulate different
environments or modifying sound perception through the use of in-game
items.
With our audio framework, players can have conversations with many
people at the same time, because the audio correctly appears to
originate from the visual location of the players that are talking.
Moreover, players are able to localize any sound source and direct
visual attention to where the sound is coming from. Note that our
method does not take reflections, refractions and interference with
other sound waves into account.
Publications
For more information and experimental results, take a look at my
Master's Thesis and the VRIC2007 paper in the publications
section.